This is the second post talking about how to integrate the use of Team Foundation Server (TFS) in a Specification by example (BDD, ATDD call it what you want) workflow. You can read the first post here for some background, but I will include some background here too, as I have thought about it some more.
Background
Specification by example is not only a way to write executable specifications (red. those words still give me the chills) but in the way it’s used in projects lies some kind of agile methodology hidden. The early and frequent communication and documentation (in a commonly understood format, Gherkin) it fosters really get the way you work in a very agile way. More on that later. Cucumber is a very well known tool in the Ruby world, where projects often create web applications. I think that this inheritance has influenced the process above, which states quick and rapid movement and very agile ways. This doesn’t sit too well with big organizations where maintainability and traceability from requirements through bugs and change requests are very important. After my last blog post I got some feedback from Hugo Häggmark and Håkan Forss that suggested different approaches to how the TFS work items could be used in this workflow. Since I haven’t used the different work item types much I got together with Hugo (who is now my colleague!) and tried to flesh things out. This is our findings.
Specification
All the work that is done before a feature is implemented should of course not be wasted but in the Specification by example process (if such a thing exists) it’s just background information. You might want to link to it or read up on it before you get together but the important “handshake” is the .feature-file and the scenarios in it. It’s here we, together write down our common understanding of the functionality. A good place to do this is in the Sprint planning meeting (for Scrum) or an early stage of your agile process.
The requirement team has, if they are using the TFS Agile template or similar, probably created user story work items for the different user stories. The .feature files that are created (with SpecFlow) are associated with their respective user story work item at check-in time, to get the link and traceability between the work items and the .feature-file. Also you can link back from the .feature-file (see earlier blog post on this).
Testing
But that’s only part of the story; the other part is testing. A very common misconception is that SpecFlow features are tests. That is wrong! A SpecFlow feature is an executable specification. When it’s implemented it can be used to see or verify which functionality your system currently implements and satisfy:
“Cucumber features are an executable map of the current functionality of the system.” - Andrew Premdas
Does this mean that you don’t need testing? What does a tester do in a working agile project that writes executable specifications? I don’t claim to be an expert on this area (I recommend Agile Testing by Lisa Crispin and Janet Gregory for an excellent deep dive into the subject), but one thing that still is left is what’s called exploratory testing:
Exploratory testing seeks to find out how the software actually works, and to ask questions about how it will handle difficult and easy cases.
So this is where you try to find the cases that you haven’t covered already. There is great support in TFS for this. For example the Microsoft Test Manager in which you can create test plans and test cases. The test case work item is used to test the user story work item that we talked about earlier, so they are linked together in a nice tight fashion. In the test cases, a series of steps are specified that the tester should take and verify the outcome. If exploratory testing is done these are often manual tests.
Bugs and test automation
But what if a bug is discovered? Well the tester then creates a bug work item type that is associated with the test case. The bug is then assigned to a developer who sees what needs to be changed to fix the bug. It might be that the scenarios we wrote in our .feature file were faulty or that the implementation didn’t do what it was supposed to. Or it might be a thing that we haven’t thought of at all. But the good news is that we can create a scenario that shows how to reproduce the bug, as a SpecFlow scenario. When that is done and the bug is fixed we can do two things to keep the traceability chain intact:
- Resolve the bug at check-in, or whatever your state diagram allows the developer to do.
- In the test case where the bug is found, the developer can create an Associated Automation. This is a field where you can point to different kinds of automated tests; among others Unit Tests. And that is the great news for us since you then can point SpecFlow scenario (or rather the generated unit-test behind it).
Recap
This picture shows the complete flow, with suggested use of the different work item types of the MSF Agile template.
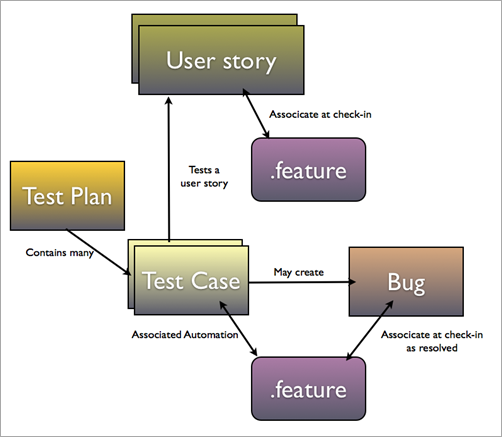
- User story work items contain the “raw” requirements and links to any documents that are needed to understand the story.
- The user story and other background information are used to create a feature file, for example in a sprint planning meeting. The feature will be our executable specification during development and afterwards serve as a regression verification of our system’s current state.
- A test leader creates a test plan to plan the exploratory testing of the system.
- This plan contains many different test cases that state how the tests should be conducted. The test cases test a user story and describe the different stages of the test, with expected outcomes.
- If a bug is found it’s assigned to a developer.
- The developer creates a scenario that shows how the bug can be reproduced.
- The scenario and the corrections in the system are associated with the bug at check-in time.
- Finally the developer returns to the test case and associates the scenario as an associated automation, for later automation.
Conclusion
This is one way to get full traceability through the whole process and still keep the specification by example / BDD process going. A big thank you goes out to Hugo, who showed me the inner workings of the MSF Agile template.